0. 前言
关于网络IO的理论知识比较凌乱,理解起来有难度,特此梳理。
1. 操作系统中的IO处理
当我们需要理解关于 IO 的时候,最好首先理解操作系统是如何处理IO的。
1.1 操作系统如何处理IO
Linux 会把所有的外部设备都看成一个文件(文件描述符fd)来操作,对外部设备的操作可以看成是对文件的操作。
我们对一个文件的读写,都会通过内核提供的系统调用,内核会给我们返回一个 File Descriptor,这个描述符是一个数字,指向内核的一个结构体,我们应用程序对文件的读写就是对描述符指向的结构体的读写。
1.2 系统调用是如何完成IO操作
Linux 会把内存分为 内核区和用户区。Linux 的内核区会帮我们管理所有的硬件资源,并且会提供系统调用,我们应用程序的读操作,就会通过系统调用 read 发起一个读操作,这个时候,内核就会创建一个文件描述符,通过驱动向硬件发送读指令,并且把读的数据放在描述符指向的结构体的缓冲区中。当这个数据传到用户区的时候,就完成了一次 IO。
Linux 系统调用的 read,是一个阻塞函数。这个我们应用程序在发起read系统调用的时候,就必须要阻塞,进程挂起,等待文件描述符的读就绪。
从上面我们可以知道,应用程序的一个 read系统调用,需要经过:
- 硬件读取文件数据到文件描述符指向的结构体的缓冲区。(等待数据准备好)
- 结构体的缓冲区的数据 传输到 用户区。(复制数据)
操作系统5种不同的IO处理,事实上就是对上述两个过程的不同处理方法。
2. 5种网络IO模型
5种模型介绍
2.1 阻塞I/O模型
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所有等待分组到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用程序缓冲区。 好,下面我们以阻塞套接字的recvfrom的的调用图来说明阻塞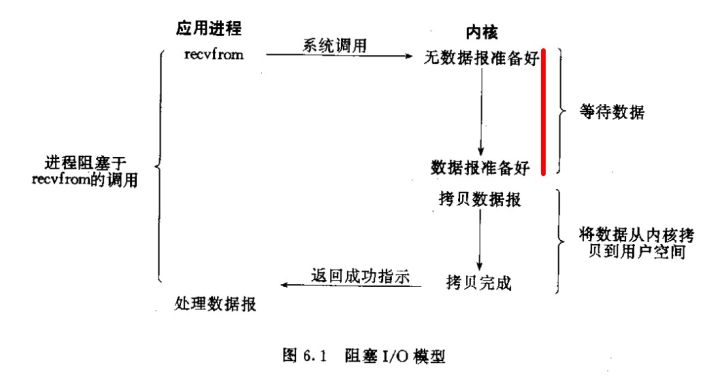
标红的这部分过程就是阻塞,直到阻塞结束recvfrom才能返回。
2.2 非阻塞I/O模型
以下这句话很重要:进程把一个套接字设置成非阻塞是在通知内核,当所请求的I/O操作非得把本进程投入睡眠才能完成时,不要把进程投入睡眠,而是返回一个错误。当一个应用程序在一个循环里对一个非阻塞调用recvfrom,我们称为轮询。
可以看出recvfrom总是立即返回。
2.3 I/O多路复用模型
I/O多路复用的函数也是阻塞的,和阻塞I/O模型非常相像,但是其与以上两种还是有不同的,I/O多路复用是阻塞在select,epoll这样的系统调用之上,而没有阻塞在真正的I/O系统调用如recvfrom之上。如图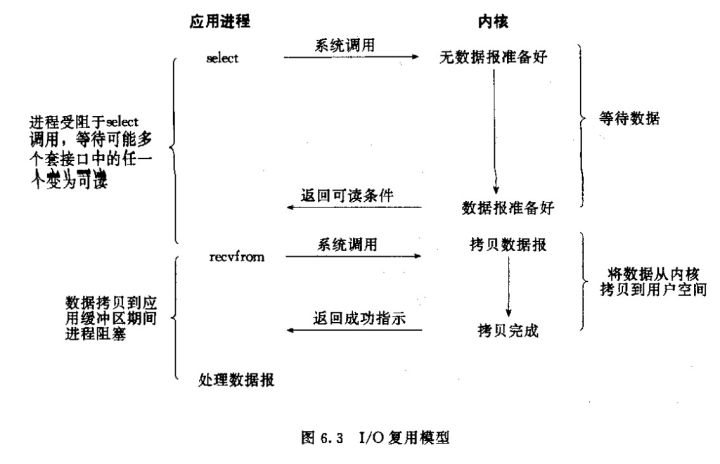
select
Linux的内核将所有外部设备都可以看做一个文件来操作,而对一个socket的读写也会有相应的描述符,称为socketfd(socket描述符)。调用select函数会阻塞,直到有描述符就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。
缺点:
1、select最大的缺陷就是单个进程所打开的FD是有一定限制的,它由FDSETSIZE设置,32位机默认是1024个,64位机默认是2048。
一般来说这个数目和系统内存关系很大,”具体数目可以cat /proc/sys/fs/file-max察看”。32位机默认是1024个。64位机默认是2048.
2、对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低。
当套接字比较多的时候,每次select()都要通过遍历FDSETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。”如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询”,这正是epoll与kqueue做的。
3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大。
poll
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。
它没有最大连接数的限制,原因是它是基于链表来存储的,
缺点:
1、大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。
2 、poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
注意:从上面看,select和poll都需要在返回后,通过遍历文件描述符来获取已经就绪的socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
epoll
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
基本原理:epoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就绪态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epollctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epollwait便可以收到通知。
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口)。
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。
只有活跃可用的FD才会调用callback函数;即Epoll最大的优点就在于它只管“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
注意:如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
2.4 信号式驱动I/O模型
用得少,不多说
2.5 异步I/O模型
这类函数的工作机制是告知内核启动某个操作,并让内核在整个操作(包括将数据从内核拷贝到用户空间)完成后通知我们。如图:
注意红线标记处说明在调用时就可以立马返回,等函数操作完成会通知我们。
其实前四种I/O模型都是同步I/O操作,他们的区别在于第一阶段,而他们的第二阶段是一样的:在数据从内核复制到应用缓冲区期间(用户空间),进程阻塞于recvfrom调用。相反,异步I/O模型在这两个阶段都要处理。
3. 同步与异步、阻塞与非阻塞
同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)
所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由调用者主动等待这个调用的结果。而异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。典型的异步编程模型比如Node.js
举个通俗的例子:你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下”,然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。
阻塞与非阻塞阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
还是上面的例子,你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己“挂起”,直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关。
在Java中:
- 同步 : 使用同步IO时,Java自己处理IO读写;
- 异步 : 使用异步IO时,Java将IO读写委托给OS处理,需要将数据缓冲区地址和大小传给OS,OS需要支持异步IO操作API;
- 阻塞 : 使用阻塞IO时,Java调用会一直阻塞到读写完成才返回;
- 非阻塞 : 使用非阻塞IO时,如果不能读写Java调用会马上返回,当IO事件分发器会通知可读写时再继续进行读写,不断循环直到读写完成
简单来说:
- 阻塞和非阻塞是针对应用程序的状态而言的
- 同步和异步是针对应用程序和OS谁处理读写而言的
4. Java中的IO
Java对BIO、NIO、AIO的支持:
Java BIO : 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
Java NIO : 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。使用Selector.select()函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,感觉效率更差。
但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,
即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。Java的实现会调用JNI,使用系统调用(select,poll,epoll)。Java的Selector.select()函数并不是直接调用系统调用select,事实上首先会判断操作系统是不是Linux,是则再判断内核版本,若版本大于等于2.6,则通过JNI使用epoll系统调用,否则使用poll系统调用。
Java AIO(NIO.2) : 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理,
BIO、NIO、AIO适用场景分析:
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK4以前的唯一选择,但程序直观简单易理解。
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK4开始支持。
AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
另外,I/O属于底层操作,需要操作系统支持,并发也需要操作系统的支持,所以性能方面不同操作系统差异会比较明显。
5. Java NIO 示例代码
下面是使用Java NIO实现的多路复用模型的服务器端代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
public class EpollServer {
public static void main(String[] args) {
try {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.socket().bind(new InetSocketAddress("127.0.0.1", 8000));
ssc.configureBlocking(false); // 重要
Selector selector = Selector.open();
// 注册 channel,并且指定感兴趣的事件是 Accept
ssc.register(selector, SelectionKey.OP_ACCEPT);
ByteBuffer readBuff = ByteBuffer.allocate(1024);
ByteBuffer writeBuff = ByteBuffer.allocate(128);
writeBuff.put("received".getBytes());
writeBuff.flip();
while (true) {
int nReady = selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> it = keys.iterator();
while (it.hasNext()) {
SelectionKey key = it.next();
it.remove();
if (key.isAcceptable()) {
// 创建新的连接,并且把连接注册到selector上,而且,
// 声明这个channel只对读操作感兴趣。
SocketChannel socketChannel = ssc.accept();
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ);
}
else if (key.isReadable()) {
SocketChannel socketChannel = (SocketChannel) key.channel();
readBuff.clear();
socketChannel.read(readBuff);
readBuff.flip();
System.out.println("received : " + new String(readBuff.array()));
key.interestOps(SelectionKey.OP_WRITE);
}
else if (key.isWritable()) {
writeBuff.rewind();
SocketChannel socketChannel = (SocketChannel) key.channel();
socketChannel.write(writeBuff);
key.interestOps(SelectionKey.OP_READ);
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
本人对于Selector.select()有一个的疑问:
Java的NIO是同步非阻塞,但为什么其核心的Selector.select()是阻塞的?不矛盾吗?
1 | Selector selector = Selector.open(); |
答:NIO 是同步非阻塞 这句话指的是对于一个IO来看,是同步非阻塞,非阻塞的意思是拥有这次IO的线程没有阻塞,而在NIO中实际上是一条线程拥有很多的IO,有任何一个IO有数据 ,selector就被唤醒,所以你可以这么想:在这条线程中,当IOA没有数据处于等待时,IOB可能正在被处理,所以这条线程并没有被这个IOA阻塞
详细可参考:Java的NIO是同步非阻塞,但为什么其核心的Selector.select()是阻塞的? - SegmentFault 思否
6. 引用
文章引用了以下文章:
- BIO与NIO、AIO的区别(这个容易理解) - CSDN博客
- Java NIO(3): IO模型 - 知乎
- Java NIO(6): Selector - 知乎
- Java IO:操作系统的IO处理过程以及5种网络IO模型 - hutongling的博客 - CSDN博客
- 怎样理解阻塞非阻塞与同步异步的区别? - 知乎
- NIO相关基础篇 - 微信公众号
Copyright © 2018, GDUT CSCW back-end Kanarien, All Rights Reserved